The purpose of this package is to allow for direct access to the NZ Freshwater Fish Database (NZFFD) from R and additional functions for cleaning imported data and adding missing data.
Specifically, the seven core functions are:
nzffdr_import()- import NZFFD data into R.nzffdr_clean()- clean up a bunch of small inconsistencies in the imported NZFFD data.nzffdr_add_dates()- add separate year, month and day columns to NZFFD data.nzffdr_taxon_threat()- add extra taxonomic and NZ Threat Classification System (NZTCS) data to NZFFD data (12 new columns). Lots more detail added compared tonzffdrv 1.0.0.nzffdr_widen_habitat()- transform non-tidy format habitat columns to tidy wide format.nzffdr_razzle_dazzle()- wrapper for all of the above functions to quickly download and tidy NZFFD data in one go.nzffdr_ind_lengths()- transform non-tidy format individual fish length measures into tidy long format.
See below for a detailed overview.
Installation
Install from CRAN
install.packages("nzffdr")Or to install the latest development version:
devtools::install_github("flee598/nzffdr")Built-in datasets
There are two built-in datasets, these are:
nzffdr_dataa subset of 200 rows from the NZFFD, used for examples, tutorials etc.nzffdr_nzmapa simple features map of New Zealand. A simplified version of the 1:150k NZ map outline available from Land Information New Zealand.
Getting data
As of Novemeber 2022 there are issues with the NIWA portal (see notes in changelog), it is best to download the entire NZFFD database (e.g. use import() with all args empty, although you can set download_format) and then filter as needed in R.
We have tried to make the search terms match those you would use directly on the NIWA site. For example leaving a search field blank will return all records. nzffdr_import() has nine search arguments:
institutionthe organisation that submitted the records.catchment_numthis refers to the Catchment No., a 6 digit number unique to the reach of interest. You can search using the individual number (e.g.catchment = "702.500"), or for all rivers in a catchment you can use the wildcard search term (e.g.catchment = "702%"), or don’t set the arg if you want all catchments in NZ.catchment_namesearch for a catchment by name e.g. (catchment_name = "Waimakariri R").waterBodysearch for a water body by name. (e.g.waterBody = "Otukaikino Stream tributary").fish_methodsearch by fishing method used. If you want to search for a specific fishing method use the functionnzffdr_get_table("fish_method")to see a list of all possible search terms, (e.g. if you only wanted fish caught by lures usefish_meth = "Angling - Lure").taxonsearch for a particular species. If you want to search for a specific species use the functionnzffdr_get_table("taxon")to see a list of all possible search terms. You can search using either common or scientific names and can search for multiple species at once. e.g. to search for Black mudfish usespecies = "Black mudfish"orspecies = "Neochanna diversus"and to search for Black mudfish and Bluegill bully usespecies = c("Black mudfish", "Bluegill bully")etc.startsstart search date. Don’t set the arg if you want all records in the database.endsend search date. Don’t set the arg if you want all records in the database.download_formatcan be eitheralloressentialdepending on how many columns of data you want.
This function requires an internet connection to query NIWA’s database.
Data citation: Stoffels R (2022). New Zealand Freshwater Fish Database (extended). The National Institute of Water and Atmospheric Research (NIWA). Sampling event dataset https://doi.org/10.15468/jbpw92
library(nzffdr)
# import all records - all fields
dat <- nzffdr_import(download_format = "all")
# To import the entire NZFF database:
# dat <- nzffdr_import()Cleaning data
While the data imported from NZFFD is in pretty good shape there are some small inconsistencies. The nzffd_clean() function aims to deal with some of these inconsistencies.Column types are checked and converted to, integer, numeric or character. Empty cells are filled with NA, variable catchmentName entries are standardised (e.g. Clutha r, Clutha River and Clutha R all become Clutha R) and, any empty columns are removed.
dat2 <- nzffdr_clean(dat)The above changes, while superficial make analysis that, for example relies on grouping, work as intended.
Add separate date columns
A small function that adds separate year, month and day columns based on values in the column eventDate.
dat3 <- nzffdr_add_dates(dat2)
# Have a look at the new columns
dat3[1:5, c("year", "month", "day")]
#> year month day
#> 1 1979 6 5
#> 2 1979 6 5
#> 3 1979 6 5
#> 4 1979 6 5
#> 5 1979 6 5Add taxonomic and threat status information
Add NZ Threat Classification System (NZTCS) information for each of the species. Includes taxonomic data, common and some Māori names. Also threat status (e.g. declining) and whether the species is endemic, invasive etc.
dat4 <- nzffdr_taxon_threat(dat3)
# Have a look at the new columns
dat4[1:5, c("commonMaoriName", "alternativeNames",
"genus", "family", "order", "class", "phylum",
"category", "status", "taxonomicStatus", "bioStatus")]
#> commonMaoriName alternativeNames genus family order
#> 1 aua kātaha, makawhiti, maraua Aldrichetta Mugilidae Mugiliformes
#> 2 aua kātaha, makawhiti, maraua Aldrichetta Mugilidae Mugiliformes
#> 3 aua kātaha, makawhiti, maraua Aldrichetta Mugilidae Mugiliformes
#> 4 aua kātaha, makawhiti, maraua Aldrichetta Mugilidae Mugiliformes
#> 5 aua kātaha, makawhiti, maraua Aldrichetta Mugilidae Mugiliformes
#> class phylum category status
#> 1 Actinopterygii Chordata Not Threatened Not Threatened
#> 2 Actinopterygii Chordata Not Threatened Not Threatened
#> 3 Actinopterygii Chordata Not Threatened Not Threatened
#> 4 Actinopterygii Chordata Not Threatened Not Threatened
#> 5 Actinopterygii Chordata Not Threatened Not Threatened
#> taxonomicStatus bioStatus
#> 1 Taxonomically Determinate Non-endemic
#> 2 Taxonomically Determinate Non-endemic
#> 3 Taxonomically Determinate Non-endemic
#> 4 Taxonomically Determinate Non-endemic
#> 5 Taxonomically Determinate Non-endemicTidy habitat columns
The NZFFD now comes with additional habitat information in the columns (habitatFlowPercent, habitatInstreamCoverPresent, habitatRiparianVegPercent, habitatSubstratePercent), by default there are multiple entries in a single cell. nzffdr_widen_habitat() transforms these non-tidy format habitat columns to tidy wide format columns.
dat5 <- nzffdr_widen_habitat(dat4)
# Have a look at the new columns
dat5[1:5, c("Fine_gravel", "Coarse_gravel", "Sand_1_2_mm", "Mud",
"Cobbles_64_257_mm", "Boulders_257_mm", "Bedrock", "Gravel_3_64_mm",
"Mud_Silt_1mm", "Run", "Riffle", "Pool", "Still", "Backwater",
"Rapid", "Cascade", "Torrent", "Grass_tussock", "Scrub",
"Native_forest", "Raupo_flax", "Exotic_forest", "Exposed_bed",
"Other", "Tussock", "Scrub_willow", "Pasture", "Undercut_banks",
"Wood_instream_debris", "Bank_vegetation", "Macrophytes_algae",
"Macrophytes", "Cobbles", "Periphyton")]
#> Fine_gravel Coarse_gravel Sand_1_2_mm Mud Cobbles_64_257_mm Boulders_257_mm
#> 1 40 40 10 <NA> <NA> 10
#> 2 40 40 10 <NA> <NA> 10
#> 3 40 40 10 <NA> <NA> 10
#> 4 40 40 10 <NA> <NA> 10
#> 5 40 40 10 <NA> <NA> 10
#> Bedrock Gravel_3_64_mm Mud_Silt_1mm Run Riffle Pool Still Backwater Rapid
#> 1 <NA> <NA> <NA> 40 40 20 0 0 0
#> 2 <NA> <NA> <NA> 40 40 20 0 0 0
#> 3 <NA> <NA> <NA> 40 40 20 0 0 0
#> 4 <NA> <NA> <NA> 40 40 20 0 0 0
#> 5 <NA> <NA> <NA> 40 40 20 0 0 0
#> Cascade Torrent Grass_tussock Scrub Native_forest Raupo_flax Exotic_forest
#> 1 0 0 0 50 50 0 0
#> 2 0 0 0 50 50 0 0
#> 3 0 0 0 50 50 0 0
#> 4 0 0 0 50 50 0 0
#> 5 0 0 0 50 50 0 0
#> Exposed_bed Other Tussock Scrub_willow Pasture Undercut_banks
#> 1 0 0 0 0 0 NA
#> 2 0 0 0 0 0 NA
#> 3 0 0 0 0 0 NA
#> 4 0 0 0 0 0 NA
#> 5 0 0 0 0 0 NA
#> Wood_instream_debris Bank_vegetation Macrophytes_algae Macrophytes Cobbles
#> 1 NA NA NA NA NA
#> 2 NA NA NA NA NA
#> 3 NA NA NA NA NA
#> 4 NA NA NA NA NA
#> 5 NA NA NA NA NA
#> Periphyton
#> 1 NA
#> 2 NA
#> 3 NA
#> 4 NA
#> 5 NAQuick all in one
There is a wrapper for all of the above functions, to quickly download the entire NZFFD, tidy and add information all in one easy step.
dat_all <- nzffdr_razzle_dazzle()
# total number of rows and columns in the dataset
dim(dat_all)
#> [1] 154866 116
# have a look at the first 5 rows and 10 columns
dat_all[1:5, 1:10]
#> nzffdRecordNumber taxonName institutionRecordNumber
#> 1 1 Anguilla <NA>
#> 2 1 Scardinius erythrophthalmus <NA>
#> 3 1 Gobiomorphus breviceps <NA>
#> 4 1 Galaxias brevipinnis <NA>
#> 5 1 Salvelinus fontinalis <NA>
#> eventDate year month day eventTime institution samplingPurpose
#> 1 1979-06-05 1979 6 5 10:30 NIWA <NA>
#> 2 1979-06-05 1979 6 5 10:30 NIWA <NA>
#> 3 1979-06-05 1979 6 5 10:30 NIWA <NA>
#> 4 1979-06-05 1979 6 5 10:30 NIWA <NA>
#> 5 1979-06-05 1979 6 5 10:30 NIWA <NA>Mapping observations
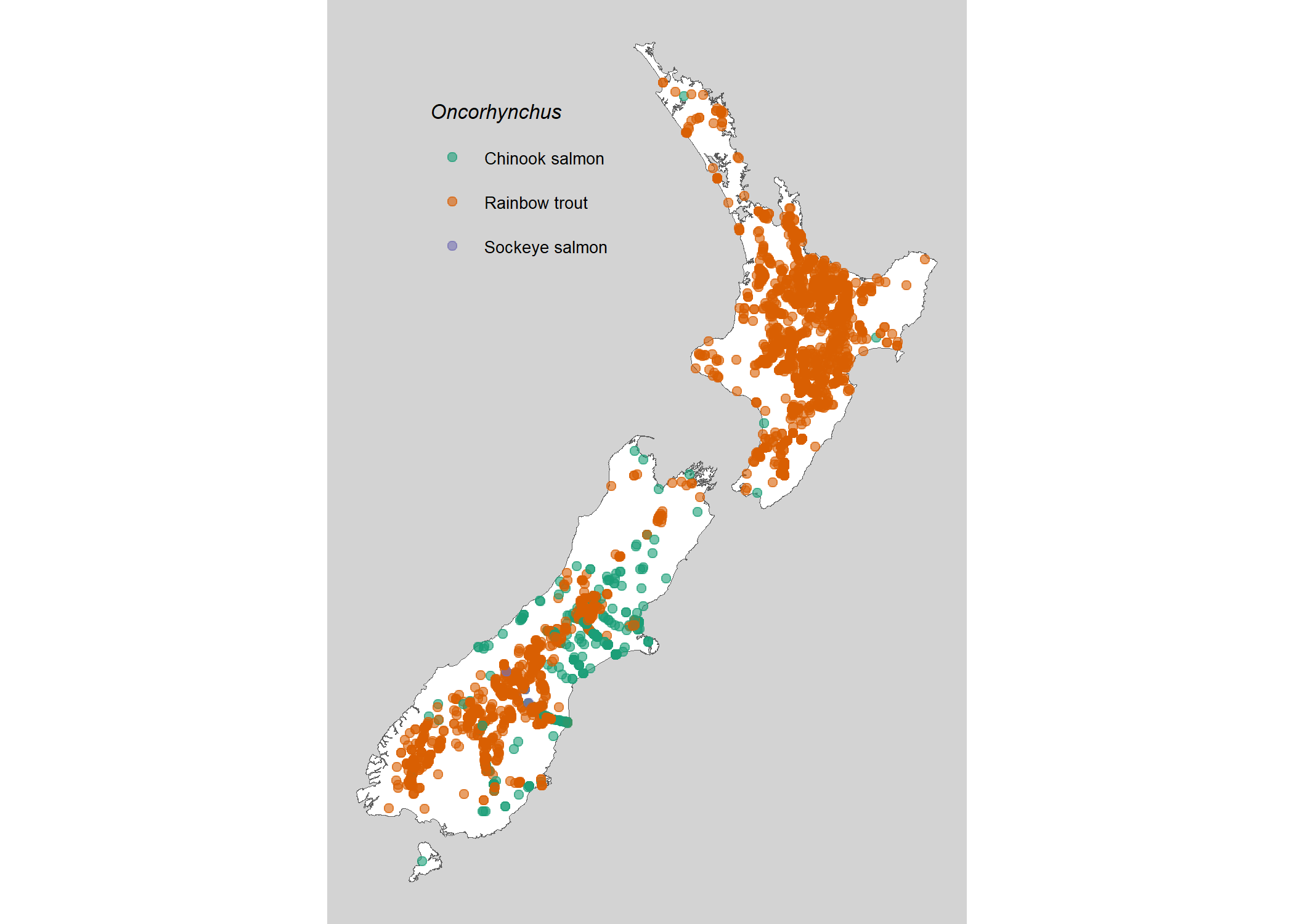
There is a simple features map of New Zealand included in the package, this can be used to quickly check species distributions and the like.
# load ggplot2 and sf for nice figures
library(ggplot2)
library(sf)
# get map of NZ and remove Chatham Islands
nz <- nzffdr::nzffdr_nzmap
nz <- subset(nz, name != "Chatham Island")
# filter just Oncorhynchus genus
df_fish <- subset(dat_all, genus == "Oncorhynchus")
# create a basic map, with points coloured by species common names
ggplot() +
geom_sf(data = nz,
fill = "white") +
geom_point(data = df_fish, aes(x = eastingNZTM, y = northingNZTM, colour = taxonCommonName),
alpha = 0.6) +
scale_colour_brewer(palette = "Dark2") +
labs(colour = expression(italic("Oncorhynchus"))) +
theme_void() +
theme(plot.background = element_rect(fill = 'lightgrey', colour = 'lightgrey'),
legend.position=c(.3, .8),
text = element_text(size = 8))